In this blog series, we will uncover the details of SLSA provenance which refers to the ability to trust the authenticity of artifacts. SLSA (Supply chain Levels for Software Artifacts) is focused on protecting software from source through its deployment by allowing users to make automated decisions about the integrity of the artifacts they use, thereby preventing many possible attacks throughout the supply chain. SLSA is a software supply chain security framework started by Google which today is backed by The Linux Foundation.
This blog series consists of 4 parts where we will dive into the details of SLSA provenance:
Part 1: Software Attestations
SLSA provenance is built on top of in-toto attestation. In-toto attestation is a framework for software attestations: a signed document that associates metadata with an artifact. In part 1, we start by understanding software attestations and how they provide integrity for artifacts and their metadata.
Part 2: SLSA Provenance
Describing the contents of SLSA provenance and the different requirements for each SLSA level. We’ll also learn how to generate them and why they're helpful.
Part 3: SLSA Provenance Level 3 and Challenges for Enterprises
One of the most challenging requirements to achieve SLSA level 3 for provenance documents is generating them in a non-falsifiable way. In this blog part, we’ll understand what it means and how you can generate non-falsifiable attestations. We’ll also learn about the limitation of current standards and technologies. We’ll explain why enterprises can’t use the standard tools to deal with closed-source software, and lay out the difficulties you may face when implementing your own provenance generation stack as an enterprise.
Part 4: Autonomous Provenance Generation for Enterprises
Finally, we will introduce a novel approach for provenance generation. With Legit Security Platform, you can integrate your SCM and CI systems in a couple of clicks, including Github, GitLab, BitBucket, Jenkins and many more. Once integrated, the platform monitors your systems and detects published artifacts, such as Docker containers and NPM packages. It then generates SLSA Level 3 provenance documents for you.
Legit’s Autonomous Provenance Generation works automatically without changing anything in your CI. It generates the provenance without exposing any of your private data, solving the challenges mentioned in part 3 of the series.
What is Artifacts Integrity, and Why is It Important
Artifacts Integrity is about the ability to trust the authenticity of artifacts, meaning verifying that the artifact you get is really the original artifact uploaded by its author.
For example, when you install 3rd-party software, you want to verify that is the authentic version created by the vendor that you trust, and that no one modified it after its creation. When you don’t verify the authenticity of the software you consume, you can easily install untrusted software that hackers crafted to look like the software you were looking for, but actually steals your information or encrypts your disks for ransomware.
Check out this blog post to learn more about it and gain technical background about hashes and signatures. This post also shows how signing containers for integrity might be more tricky than expected.
What is Software Attestations, and what can you use it for
Proving the integrity of your software artifacts is essential, but it is not enough: although it enables users to trust the artifacts that they consume, it does not provide any trusted context to that artifact.
Software is seldom consumed without context, often referred to as metadata, which includes details such as:
-
The version of the software.
-
The origins of the source code - its git repository, branch, tag, etc.
-
The build process from which it was created - the CI system, pipeline/job, etc.
-
The external dependencies used to build it (did anyone say SBOM?).
-
The test suites that ran on it.
-
The security checks that it passed.
We can continue adding bullets, but you probably got the idea by now - WE WANT TO KNOW MORE!
That’s exactly the purpose of software attestation: providing trusted context for software artifacts.
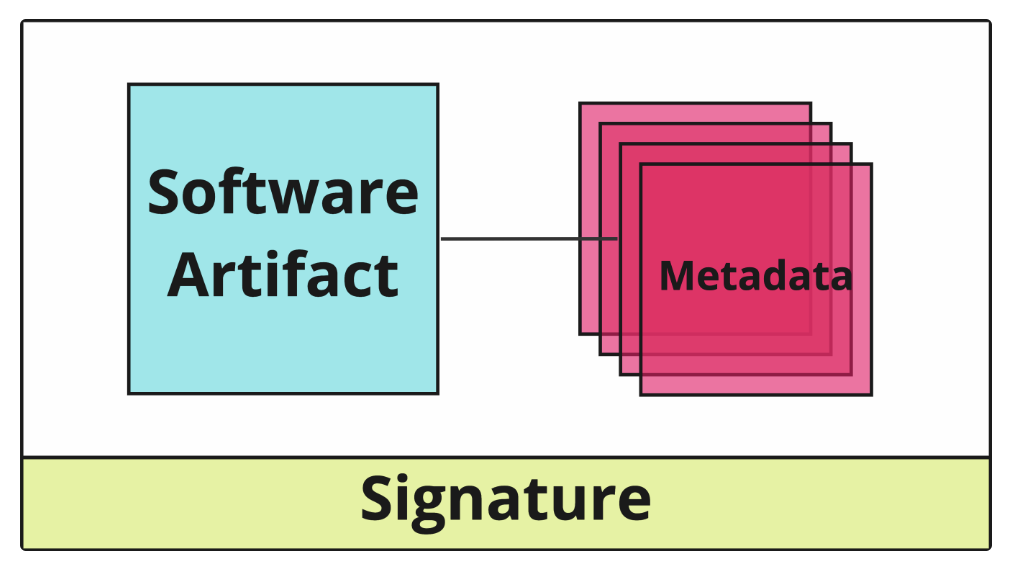 Software Attestation: just a signed bundle of a software artifact(s) and its metadata.
Software Attestation: just a signed bundle of a software artifact(s) and its metadata.
Now that we understand the idea on an abstract level, let’s dive into in-toto attestations: the leading open-source project for software attestations.
What is in-toto attestation framework
In-toto attestation is a still-in-development open source framework for software attestations, backed by The Linux Foundation. It’s part of the wider in-toto project that aims to protect software supply chains. The specification for in-toto attestations can be broken down to three layers:
-
The DSSE Envelope (“Dead Simple Signing Envelope”): the transport layer.
-
The in-toto Statement: the attestation header.
-
The predicate: the attestation payload.
Let’s dive into it top-down.
The DSSE Envelope: providing the secure transport layer
The DSSE envelope carries the the statement of the attestation and provides the cryptographic context needed to verify the authenticity of the attestation.
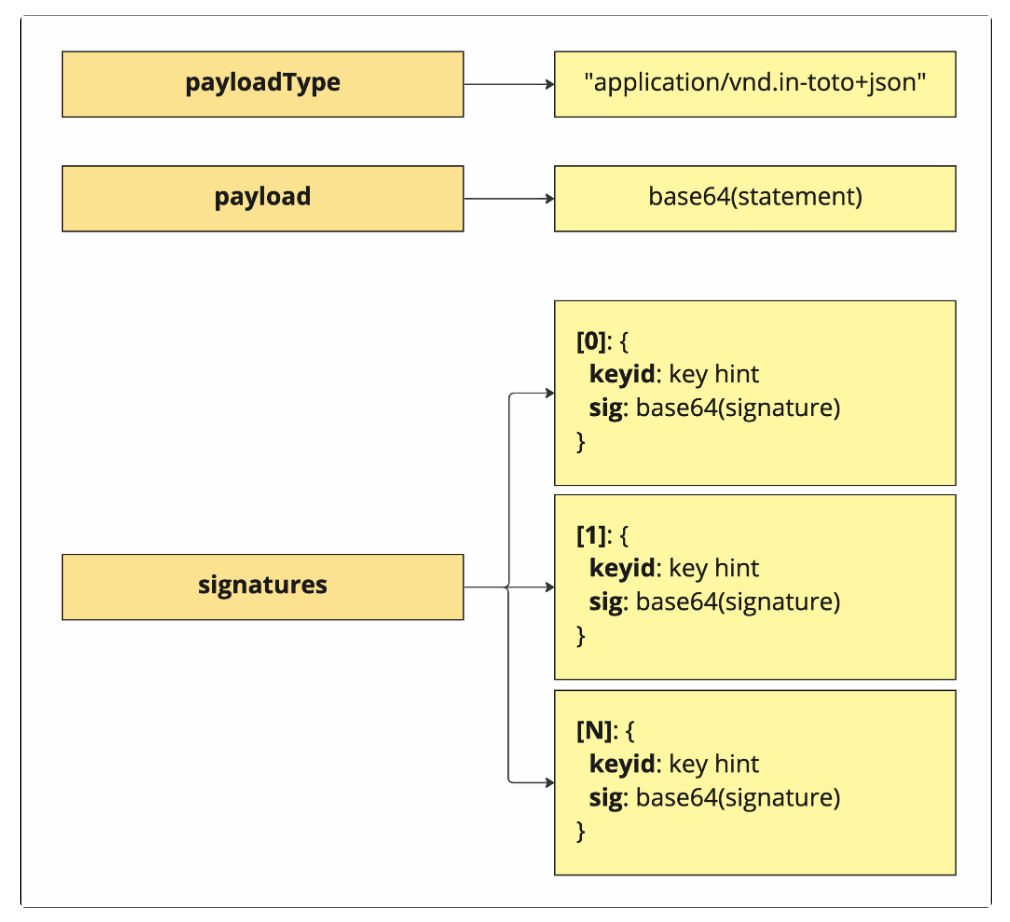 The DSSE Envelope Layout
The DSSE Envelope Layout
Payload Type
It is always set to
application/vnd.in-toto+json, which indicates that it is a JSON object with a _type field indicating its schema (we’ll go into it when we dive into the statement).Payload
This is the statement of the attestation, encoded with base64.
Signatures
This is a list of one or more signature fields.
Each such signature field is comprised of two fields:
-
Key ID: An optional field, used as a hint for the signing key. This field cannot be trusted! Its main purpose is to allow the verifier to choose the relevant public key more easily, i.e. from a list of already-trusted public keys / certificates.
-
Sig: This is the actual signature, encoded with base64.
Some readers may notice that the in-toto envelope does not specify a field for certificate chains.
Indeed, the DSSE envelope protocol leaves certificate management to be handled out of band.
Fortunately, the spec allows usage of external fields, so one might embed certificates nonetheless. That can become very useful, and, for instance, the SigStore project adds a cert field for that purpose.
The in-toto Statement: identifying the nature of the predicate
The statement is the middle-layer of the attestation. It carries the actual predicate, and provides the binding to the specific artifacts being attested.
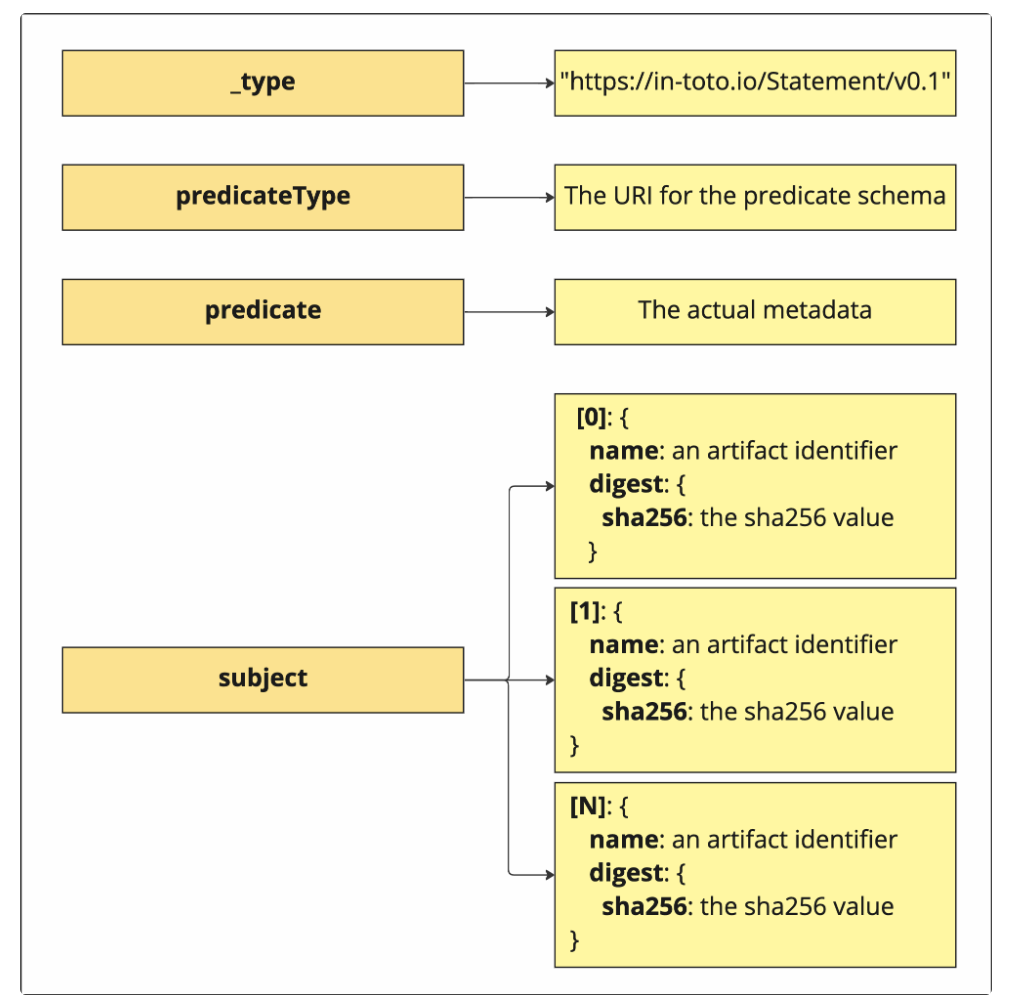 The in-toto attestation Layout
The in-toto attestation Layout
_type
The _type field simply identifies the encoding of the payload.
It is always set to https://in-toto.io/Statement/v0.1 (for the current version), which indicates that it is a statement containing the following fields.
predicateType
The predicate type is a URI identifying the content of the payload.
Anyone can use any predicate type they would like for their own purposes, but some predicate types are recognized by the in-toto framework:
-
SLSA Provenance (https://slsa.dev/provenance/v0.1)
-
SCAI (https://in-toto.io/scai/attribute-report/v0.1)
-
SPDX SBOM (https://spdx.dev/Document)
subject
The subject field identifies the artifacts associated with this attestation. An attestation can refer to one or more artifacts, and the subject field may contain one or more subjects, respectively.
Each artifact is represented using two fields:
1. name: a unique name describing the artifact.
2. digest: a map with hash representations of the artifact, where each key is an hash algorithm and each value is the hash value for that algorithm.
SHA256 is most commonly used as the hash algorithm for attestation, but different implementations might prefer using different algorithms. A hash value of an artifact maps directly to its content. As a result, a hash value identifies the very specific version of the artifact.
predicate
The predicate is the metadata that associated with the artifact, as a json object. It is a set of key-value pairs that contain the info that we would like to associate with the artifact. The content of this object is derived from the value of the predicateType field.
This might include the provenance (description of the origins of the artifact), SBOM (description of the contents and dependencies of the artifact), security checks such as SAST/DAST, and more.
What’s next?
In part 2, we’ll dive into the provenance attestation. We’ll uncover the details of the SLSA provenance: what it contains, how it is generated, and how you can use it to improve your software supply chain.
So far, we described how attestations enable software authors to associate metadata about the artifact in a trusted manner. In the next chapters, we’ll describe non-falsifiable attestations and why they are crucial for advanced security. We’ll also point out limitations and challenges with existing attestation technologies and describe methods to overcome them.
Looking for help with Software Attestations or SLSA Provenance?
Although it’s important to learn about these technologies, adopting them requires some expertise. Today, the SigStore project is a popular way to start integrating attestations and provenance into your CI/CD pipelines. Unfortunately, SigStore operates in an open-source minded approach, uploading your private information to public logs.
Contact Legit Security if you’re looking for an alternative that fits enterprise needs (complete data privacy, independent of your production environment on 3rd-party service, and more).
Up Next
Thank you for reading the SLSA Provenance Blog Series, Part 1: What Is Software Attestation. Read the next installment, SLSA Provenance Blog Series, Part 2: Deeper Dive Into SLSA Provenance.