


Gain insights into GenAI applications and how they represent an innovative category of technology, leveraging Large Language Models (LLMs) at their core.
Introduction
GenAI applications represent an innovative category of technology, leveraging Large Language Models (LLMs) at their core to implement new types of applications, such as autonomous agents, or to revolutionize old ones, such as chatbots.
In this blog, I will lay down the foundations for securing Generative AI (GenAI) based applications as we know them today. The architecture behind these applications is called Return Augmented Retrieval (RAGs), and I explain it in the background section. If you're currently developing or considering developing such an application, this post is a must-read for you!
The Importance of Visibility
Before we explore the technical aspects of these applications, it's crucial to emphasize the significance of visibility in this domain. GenAI applications present unique security challenges, partly due to their novelty and the evolving nature of associated risks. Understanding the full spectrum of potential risks is an ongoing process.
While the guidelines and recommendations in this blog will significantly help secure applications, it's important to begin this journey with a comprehensive understanding of your GenAI stack. This means identifying and familiarizing yourself with the various components used, including:
- GenAI models
- Vector databases
- Third-party libraries
- Prompts
Listing and understanding these elements is the first step in building a secure development pipeline that can ensure these components adhere to security best practices, such as undergoing a thorough code review.
Background
The typical GenAI-based application architecture is often also referred to as RAG (Return-Augmented Generation).
The main components of a Gen-AI or RAG app are:
-
Large Language Model (LLM): Serves as the central processing unit of the application.
-
Vector Database: Acts as the repository for the application's memory.
-
Plugins/Tools: Comprises a suite of tools that the LLM utilizes to fulfill the software's objectives, such as script execution and API usage.
-
Conventional Software Components: Includes elements like the user interface and databases.
When a user engages with a GenAI-based application through prompts, the vector database retrieves data, which is then processed by the LLM. Following this, the application either activates plugins or responds directly to the user's inquiry based on the LLM's output.
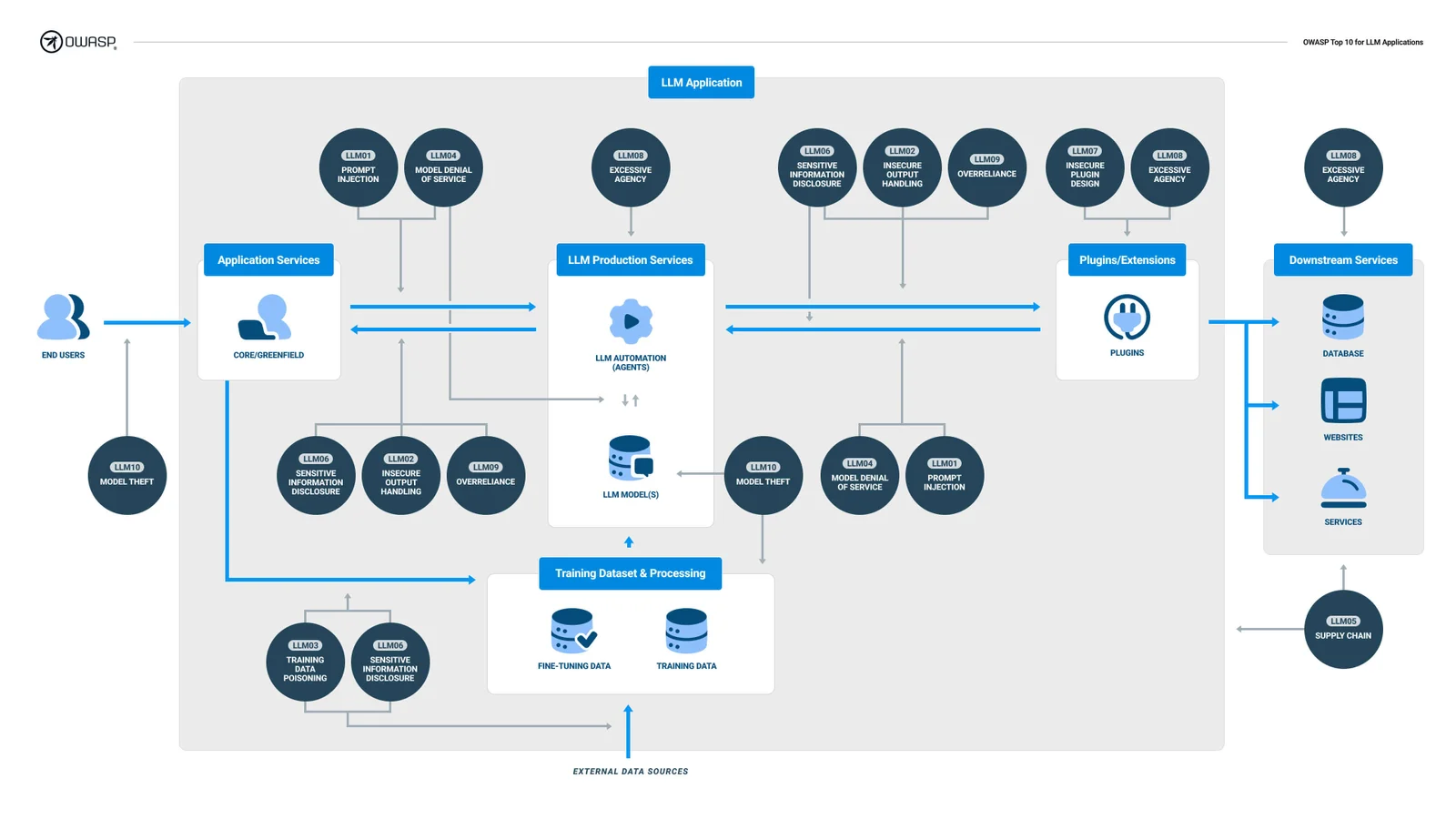 Overview of a typical GenAI-based application architecture (Source)
Overview of a typical GenAI-based application architecture (Source)
This innovative software architecture introduces a spectrum of unique vulnerabilities that need to be considered.
LLM Top Risks (Based on OWASP Top 10 and BIML Top 10):
The OWASP Top 10 for Large Language Model Applications project aims to educate developers, designers, architects, managers, and organizations about the potential security risks when deploying and managing Large Language Models (LLMs).
Berryville Institute of Machine Learning (BIML) is a leading organization in the realm of Machine learning security. They research architectural risks in AI and ML development and integrations. Their work is well accepted in the industry and implemented internally by leading ML organizations like Google and various government organizations.
These lists provide the basis for this post and provide good guidance into the security of LLMs
Data Risks:
Training Data Poisoning
In the context of GenAI applications, training data poisoning refers to the possibility of controlling the data in the vector database (i.e., the model memory), potentially leading to indirect prompt injection and misleading the users.
Prompt Risks:
Prompt Injection
Prompt Injection Vulnerabilities in LLMs involve crafty inputs leading the LLM to behave in a way it wasn’t supposed to. That way, attackers could lead the LLM to disclose private information or create a malicious output that would compromise the GenAI application.
Indirect Prompt Injection
This is similar to Prompt Injection risks, with the difference being that the prompt is introduced from an indirect source, such as a website, data store, or PDF. This could be when the LLM is used to interact with external sources (see Prompt Injections are bad, mkay?).
Output Risks:
Insecure Output Handling
These occur when plugins or apps accept LLM output without scrutiny, potentially leading to Cross-Site Scripting (XSS), Server-Side Request Forgery (SSRF), privilege escalation, and remote code execution, and can enable agent hijacking attacks.
Business Risks:
Model Denial of Service
An attacker interacts with an LLM in a way that is particularly resource-consuming, causing quality of service to degrade for them and other users.
High Costs
An attacker interacts with an LLM in a way that causes high resource costs to be incurred (also called sponge attacks).
Development Risks:
Supply Chain Vulnerabilities
LLM supply chains risk integrity due to vulnerabilities leading to biases, security breaches, or system failures. Issues arise from pre-trained models, crowdsourced data, and plugin extensions.
Insecure Plugin Design
Plugins can be prone to malicious requests, leading to harmful consequences like data exfiltration, remote code execution, and privilege escalation due to insufficient access controls and improper input validation. Developers must follow robust security measures to prevent exploitation, like strict parameterized inputs and secure access control guidelines.
Sensitive Information Disclosure:
LLM applications can inadvertently disclose sensitive information, proprietary algorithms, or confidential data, leading to unauthorized access, intellectual property theft, and privacy breaches. To mitigate these risks, LLM applications should employ data sanitization, implement appropriate usage policies, and restrict the types of data returned by the LLM.
Recommendations
For Vector databases:
Vector stores (MongoDB, Pinecone, ChromaDB, Posgres, etc.) contain the data your application is using in order to perform its function. It is used to build the context that is sent to the LLM and, as a result, to the user. In case of prompt compromise (i.e., in a prompt injection attack), it could lead to data leakage and poisoning, and therefore, it is recommended to:
-
Implement scoped access per user or tenant basis to ensure that the LLM processes only data that is relevant to the current user. [Sensitive Information Disclosure]
-
Populate vector databases through the application, not the user. The data stored in the vector stores is used to construct the prompt that is sent to the model. By controlling it you reduce the chance for indirect prompt injection. [Indirect Prompt Injection]
-
Establish distinct vector stores for different applications. [Sensitive Information Disclosure]
For Plugins/Tools:
Tools are used to provide the LLM a way to interact with the “world” (e.g., external service, execution code, etc.). In case of prompt compromise, it could lead to severe consequences such as Remote Code Execution (RCE), SSRF, data leakage, and much more. Therefore, it is recommended you:
-
Ensure API authentication tokens have minimal required permissions. [Insecure Plugin Design]
-
Scope API authentication to the current user. [Insecure Plugin Design, Sensitive Information Disclosure]
-
Run script-executing tools within a sandbox environment. [Insecure Plugin Design]
-
Restrict access to the internal production network. [Insecure Plugin Design]
-
Design tools with minimal necessary privileges and permissions. [Insecure Plugin Design, Sensitive Information Disclosure]
-
Incorporate human-in-the-loop approval prior to execution. [Insecure Output Handling]
For Prompt Injections:
Prompts are critical for interaction with the LLM and often serve as the primary entry point in GenAI-based applications. Attackers who manage to manipulate the prompt that goes into the LLM could take over the GenAI app. Therefore, it is recommended you:
-
Where feasible, construct the prompt within your application, and don’t let the user have full control of it.
-
Encode prompts into structured formats (JSON, YAML, etc.). [Prompt Injection, Indirect Prompt Injection]
-
Maintain control over prompt context length. [Prompt Injection, Indirect Prompt Injection, High Costs, Model Denial Of Service]
-
Employ two-stage prompt construction - Ask a “sandboxed” model to summarize the user prompt before you construct the final prompt. [Prompt Injection, Indirect Prompt Injection]
-
Employ a prompt scanner for additional security (Prompt Injection - LLM Guard, 📚 LLM scan - Giskard Documentation ). [Prompt Injection, Indirect Prompt Injection]
For Denial of service:
Considering the resource-intensive nature of LLM computations, attackers might target GenAI applications to cause a Denial of Service (DoS) or to exploit LLM resources. Therefore, it is recommended you:
-
Enforce strict rate limits on applications that use GenAI. [High Costs, Model Denial Of Service]
-
Limit prompt size. [High Costs, Model Denial Of Service]
For Sensitive Information Disclosure:
Generative AI-based applications often store sensitive information that could inadvertently be embedded in LLM prompts, leading to unintentional disclosure to third parties or unauthorized users. Therefore, it is recommended you:
-
Limit information stored in vector databases
-
Utilize dedicated vector stores for specific use cases
In conclusion
To effectively secure Generative AI-based applications, it's essential to prioritize visibility and a thorough understanding of the system's architecture and potential vulnerabilities. By identifying and controlling the risks in areas such as data handling, prompt management, and plugin security, organizations can build a more resilient defense against threats. Implementing the security measures outlined in this blog will help you do that. Ultimately, a proactive approach to security, grounded in visibility and comprehension, is key to navigating the challenges of Generative AI.